
|
| |
|
Строительный блокнот Automata methods and madness 2.4 An Application: Text Search In this section, we shall see that the abstract study of the previous section, where we considered the problem of deciding whether a sequence of bits ends in 01, is actually an excellent model for several real problems that appear in applications sucli as Web search and extraction of information from text. 2.4.1 Finding Strings in Text A common problem in the age of the Web and other on-line text repositories is the following. Given a set of words, find all documents that contain one (or all) of those words. A search engine is a popular example of this process. TJie searcli engine uses a particular technology, t:alled inverted indexes, where for each word appearing on the Web (there are 100,000,000 different words), a list of all the places where that word occurs is stored. Machines with very large amormts of main memory keep the most common of these lists available, allowing many people to search for documents at once. Inverted-index techniques do not make use of finite automata, but they also take very large amounts of time for crawlers to copy the Web and set up the indexes. There are a number of related applications that are unsuited for inverted indexes, but are good applications for automaton-based techniques. The characteristics that make an application suitable for searches that use automata are: 1. The repository on which the search is conducted is rapidly changing. For example: (a) Every day, news analysts want to search the days on-line news articles for relevant topics. For example, a financial analyst might seardh for certain stock ticker symbols or names of companies. Exercise 2.3,5: In the only-if portion of Theorem 2.12 we omitted the proof by induction on \w\ that if So{qo,w) = P then 5;>f{q(,.w) = {p}. Supply this proof. ! Exercise 2.3.6: In the box on Dead States and DFAs Missing Some Transitions, we claim that if N is an NFA that has at most one choice of state for any state and input symbol (i.e., 5{q, a) never has size greater than 1), then the DFA D constructed from by the subset construction has exactly the states and transitions of plus transitions to a new dead state whenever Л is missing a transition for a given state and input symbol. Prove this contention. Exercise 2.3.7: In Example 2.13 we claimed that the NFA N is in state qi, for г = 1,2,.... п.. after reading input sequence w if and only if the ith symbol from the end of ш is 1. Prove this claim. (b) A shopping robot wants to search for the current prices charged for the items that its clients request. The robot will retrieve current catalog pages from the Web and then search those pages for words that suggest a price for a particular item. 2. The documents to be searched cannot be cataloged. For example, Amazon.com does not make it easy for crawlers to find all the pages for all the books that the company sells. Rather, these pages are generated on the fly in response to queries. However, we could send a query for books on a certain topic, say finite automata, and then search the pages retrieved for certain words, e.g., excellent in a review portion. 2.4,2 Nondeterministic Finite Automata for Text Search Suppose we are given a set of words, which we shall call the keywords, and we waM to find occurrences of any of these words. In applications such as these, a useful way to proceed is to design a nondeternnnistic finite automaton, which signals, by entering an accepting state, that it has seen one of the keywords. The text of a document is fed, one character at a time to this NFA, which then recognizes occurrences of the keywords in this text. There is a simple form to an NFA that recognizes a set of keywords. 1. There is a start state with a transition to itself on every input symbol, e.g. every printable ASCII character if we are examining text. Intuitively, the start state nprcsents a guess that wc have not yet begun to see one of the keywords, even if we liave seen some letters of one of these words. 2. For each keyword a\a2 - (ik, there are к states, say gi, 92, , gt- There is a transition from the start state to qi on symbol oi, a transition from qi to q2 on symbol 02, and so on. The .state is an accepting state and indicates that the keyword 1 2 uit has been found. Example 2.14: Suppose we want to design an NFA to recognize occurrences of the words web and ebay. The transition diagram for the NFA designed using the rules above is in Fig, 2.16. State 1 is the start state, and we use S to stand for the set of all printable ASCII characters. States 2 through 4 have the job of recognizing web, while states 5 through 8 recognize ebay, □ Of course the NFA is not a program. We have two major choices for an implementation of this NFA. 1. Write a program that simulates this NFA by computing the set of states it is in after reading each input sjmbol. The simulation was suggested in Fig. 2.10. 2. Convert the NFA to an equivalent DFA using the subset construction. Then simulate the DFA directly. 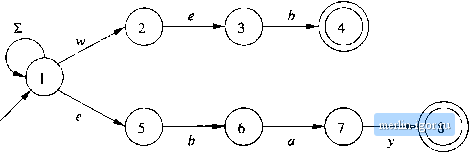 Start Figure 2.16: An NFA that searches for the words web and ebay Some text-processing programs, such as advanced forms of the UNIX grep command (egrep and f grep) actually use a mixture of these two approaches. However, for our purposes, conversion to a DFA is easy and is guaranteed not to increase the number of states. 2.4.3 A DFA to Recognize a Set of Keywords We can apply the subset construction to any NFA. However, when we apply that construction to an NFA that was designed from a set of Iceywords, according to the strategy of Section 2.4.2, we find that the number of states of the DFA is never greater than the number of states of the NFA. Since in the worst case the number of states exponentiates as we go to the DFA, this observation is good news and explains why the method of designing an NFA for keywords and then constructing a DFA from it is used frequently. The rules for constructing the set of DFA states is as follows. a) If qo is the start state of the NFA, then {qo} is one of the states of the DFA. b) Suppose p is one of the NFA states, and it is reached from the start state along a path whose symbols are aiOa a- Then one of the DFA states is the set of NFA states consisting of: 1. qo. 2. p. 3. Every other state of the .NFA that is reachable from qo by following a path whose labels are a suffix of aiaa - йщ, that is, any sequence of symbols of the form ujuj+i am- Note that in general, there will be one DFA state for each NFA state p. However, in step (b), two states may actually yield the same set of NFA states, and thus become one state of the DFA. For example, if two of the keywords begin with the same letter, say a, then the two NFA states that are reached from qo by an
|