
|
| |
|
Строительный блокнот Automata methods and madness !! Exercise 3.1.3: Write regular expressions for the following languages: a) The set of all strings of Os and Is not containing 101 as a substring. b) The set of all strings with an equal number of Os and Is, such that no prefix has two more Os than Is, nor two more Is than Os. c) The set of strings of Os and 1 s whose imniber of Os is divisible by five and whose number of 1 s is even. ! Exercise 3.1.4: Give English descriptions of the languages of the following regular expressions: * a) {l + f)(00*l)0*. b) (0*1*)*000(0 + 1), c) {0 + 10)*!. *1 Exercise 3.1.5: In Example 3.1 we pointed out that 0 is one of two languages whose closure is finite. What is the other? 3.2 Finite Automata and Regular Expressions Wliile the regular-expression approach to describing languages is fundamentally different from the finite-automaton approach, these two notations turn out to represent exactly the same set of languages, which we have termed the regular languages. We have already shown that deterministic finite automata, and the two kinds of nondeterministic finite automata -- with and without E-transitions - accept the same class of languages. In order to show that the regnlar expressions define the same class, we must show that: 1. Every language defined by one of these automata is also defined by a regular expression. For this proof, we can assume the language is accepted by some DFA. 2, Every language defined by a regular expression is defined by one of these automata. For this part of the proof, the easiest is to show that there is an NFA with e-transitions accepting the same language. Figure 3.1 shows all the equivalences we have proved or will prove. An arc from class X to class Y means that we prove every language defined by class X is also defined by class Y. Since the graph is strongly connected (i.e., we can get from each of the four nodes to any other node) we see that all four classes are really the same. 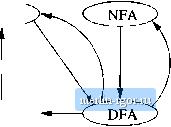 Figure 3,1: Plan for showing the equivalence of four different notations for regular languages 3.2.1 From DFAs to Regular Expressions The construction of a regular expression to define the language of any DFA is surprisingly tricky. Rougiily, we build expressions that describe sets of strings that label certain paths in the DFAs transition diagram. However, the paths are allowed to pass through only a limited subset of the states. In an inductive definition of these expressions, we start with the simplest expressions that describe paths that are not allowed to pass through any states (i.e., they are single nodes or single arcs), and inductively build the expressions that let the paths go through progressively larger sets of states. Finally, the paths are allowed to go through any state; i.e., the expressions we generate at the end represent all possible paths. These ideas appear in the proof of the following theorem. Theorem 3.4: If l = l{a) for some DFA A, then there is a regular expression r sucli that l = l{r). PROOF: Let us suppose that As states are (1,2 , n} for some integer n, .No matter what the states of .4 actually are, there will be n of them for some finite n, and by renaming the states, we can refer to the states in this manner, as if they were the first n positive integers. Our first, and most difficult, task is to construct a collection of regular expressions that describe progressively broader sets of paths in the transition diagram of a. Let us use as the name of a regular expression whose language is the set of strings vj such that w is the label of a path from state г to state j m a, and that path has no intermediate node whose number is greater than k. Note that the begiiming and end pouits of the path are not intermediate, so there is no constraint that i and/or j be less tlian or equal to k. Figure 3.2 suggests the requirement on the paths represented by r\j . There, the vertical dimension represents the state, from 1 at the bottom to n at the top, and the horizontal dimension represents travel along the path. Notice that in tiiis diagram we have shown both i and j to be greater than k, but either or both could be к or less. Also notice that the path passes through node к twice, but never goes through a state higher than fc, except at the endpoints. Figure 3.2: A path whose label is in the language of regular expression R) To construct the expressions R\j \ we use the following inductive definition, starting at fc - 0 and finally reaching к = n. Notice that when к = n, there is no restriction at all on the paths represented, since there are no states greater than n. BASIS: The basis is = 0. Since all states are numbered 1 or above, the restriction on paths is that the path mast have no intermediate states at all. There are only two kinds of paths that meet such a condition: 1. An arc from node (state) i to node j. 2. A path of length 0 that consists of only some node i. If г Ф j, then ordy case (1) is possible. We must examine the DFA A and find those input symbols a such that there is a transition from state i to state j on symbol a. a) If there is no such symbol a, then R = 0. b) If there is exactly one such symbol a, then R - a. c) If there are symbols 1,2,..., а. that label arcs from state i to state j, then Rlf = ai + 32 + + aA,. However, if i = j, then the legal paths are the path of length 0 and all loops from i to itself. The path of length 0 is represented by the regular expression 6, since that path has no symbols along it. Thus, wc add e to the various expressions devised in (a) through (c) above. That is, in case (a) [no symbol o] the expression becomes e, in case (b) [one symbol a] the expression becomes €+a, and in case (c) [multiple symbols] the expression becomes с + ai + a- +----h&k- INDUCTION: Suppose there is a path from state г to state j that goes through no state higher than k. There arc two possible cases to consider:
|