
|
| |
|
Строительный блокнот Automata methods and madness This expression is 1*0(0 + 1). It is simple to interpret this expression. Its language consists of all strings that begin with zero or more Is, then have a 0, and then any string of Os and Is. Put another way, the language is a!! strings of Os and Is with at least one 0. □ 3.2.2 Converting DFAs to Regular Expressions by Eliminating States The method of Section 3.2.1 for converting a DFA to a regular expression always works. In fact, iia you may have noticed, it doesnt really depend on the automaton being deterministic, and could just as well have been applied to an NFA or even an e-NFA. However, the construction of the regular expression is expensive. Not only do we have to construct about n expressions for an n-state automaton, but the length of the expression can grow by a factor of 4 on the average, with each of the n inductive steps, if there is no simplification of the expressions. Thus, the expressions themselves could reacli on the order of 4 sjmibols. There is a similar approach that avoids duplicating work at some points. For example, all of the expressions with superscript (k + 1) in the construction of Theorem 3.4 use the same subexpression (R(,)*; the work of writing that expression is therefore repeated times. The approach to constructing regular expressions that we shall now learn involves eliminating states. When we eliminate a state s, all the paths that went through 5 no longer exist in the automaton. If the language of the automaton is not to change, we must include, on an arc that goes directly from q to p, the labels of paths that went from some state q to state p, through s. Since the label of this arc may now involve strings, rather than single symbols, and there may even be an infinite number of such strings, we cannot simply fist the strings as a label. Fortunately, there is a simple, finite way to represent all such strings: use a regular expression. Thus, we are led to considtr automata that have r(!gular (ixpressions as labels. The language of the automaton is the union over all paths from the start state to an accepting state of the language formed by concatenating the languages of the regvdar expressions along that path. Note that this rule is consistent with the defirntion of the language for any of the varieties of autonmta we have considered so far. Each s-mbol a, or e if it is allowed, can be thought of as a regular ejcpression whose language is a single string, either {a} or {e}. We may regard this observation as the basis of a state-elimination procedure, which we describe next. Figure 3.7 shows a generic state s about to be eliminated. We suppose that the automaton of which я is a state has predecessor states (/i, 921 > *7i- iov s and successor states pi,P2, - Pm for s. It is possible that some of the qs are also ps, but we assume that s is not among the gs or ps, even if there is a loop from ,4 to itself, as suggested by Fig. 3.7. We also show a regular expression on each arc from one of the qs to s; expression labels the arc from qi- Likewise, 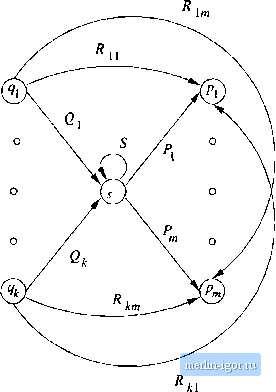 Figure 3.7: A state s about to be eliminated wo show a regular expression Pj labeling the arc irom s to Pi, for all i. We show a loop on .3 with label 5. Finally, there is a regular expression Rij on the arc from Qi to pj, for all i and j. Note that some of these arcs may not exist in the automaton, in which case we take the expression on that arc to be 0. Figure 3.8 shows what happens when we eliminate state з. All arcs involving state 5 are deleted. To compensate, wo introduce, for each predecessor qt of s and each successor Pj of s, a regular expression that represents all the paths that start at qi, go to s, perhaps loop around s zero or more times, and finally go to Pj. The expression for these paths is QiS*Pj. This expression is added (with the union operator) to the axe from qi to Pj. If there was no arc qi Pj, tiien first introduce one with regular expression 0. The strategy for constructing a regular expression from a finite automaton is as follows: 1. For each accepting state q, apply the above reduction process to ])ro-duce an equivalent automaton with regular-expression labels on the arcs. Eliminate all states except q and the start state qo. 2. Иq Ф qo, then we shall be left with a two-state automaton that looks like ® 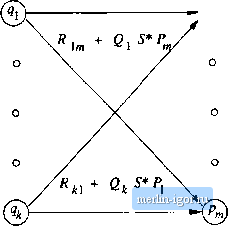 Figure 3.8; Result of eliminating state s from Fig. 3,7 Fig. 3,9, The regular expression for the accepted strings can be described in various ways. One is {R + SU*T)*SU*. In explanation, we can go from the start state to itself any number of times, by following a sequence of paths whose labels Eue in either L(R) or L{SUT). The expression SUT represents paths that go to the accepting state via a path in L{S), perhaps return to the accepting state several times using a sequence of paths with labels in L{U), and then return to the start state with a path whose label is in L{T). Then we must go to the accepting state, never to return to the start state, by following a path with a label in L{S). Once in the accepting state, we can return to it as many times as we like, by following a path whose label is in L (17), 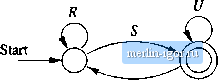 Figure 3,9: A generic two-state automaton 3. If the start state is also an accepting state, then we must also perform a state-elimination from the original automaton that gets rid of every state but the start state. When we do so, we are left with a one-state automaton that looks hke Fig. 3.10. The regular expression denoting the
|