
|
| |
|
Строительный блокнот Automata methods and madness All of the automata we construct are e-NFAs with a single accepting state. Theorem 3.7: Every language defined by a regular expression is also defined by a finite automaton. PROOF: Suppose L = L{R) for a regular expression R. We show that L - L{E) for some e-NFA E with: 1. Exactly one accepting state. 2. No arcs into the initial state. 3. No arcs out of the accepting state. The proof is by structural induction on R, following the recursive definition of regular expressions that we had in Section 3.1.2. 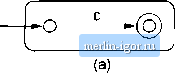 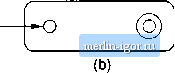 Figure 3.16: The basis of the construction of an automaton from a regular expression BASIS: There are three parts to the basis, shown in Fig. 3.16. In part (a) we see how to handle th<; expression e. The language of the automaton is easily seen to be { }, since the only path from the start state to an accepting state is labeled e. Part (b) shows the construction for 0. Clearly there are no paths from start state to accepting state, so 0 is the language of this automaton. Fintdly, part (c) gives the automaton for a regular expression a. The language of this automaton evidently consists of the one string a, whicli is also L{a). It is easy to check that these automata all satisfy conditions (1), (2), and (3) of the inductive hypothesis. 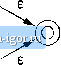 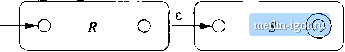 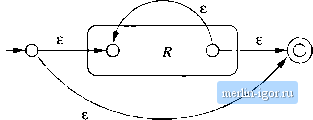 Figure 3.17: The induetive step in the regular-expression-to-e-NFA construction INDUCTION: The three parts of the induction are shown in Fig. 3.17. We assume that the statement of the theorem is true for the immediate subexpressions of a given regular- expression; tliat is. the languages of these subexpressions are also the languages of e-NFAs with a single accepting state. The four <:ases are: 1. Ttie expression is Л -Ь 5 for some smaller expressions R and 5. Then the automaton of Fig. 3.17(a) serves. That is, starting at the new start state, we can go to the start state of either the automaton for R or the automaton for S. We then reach the accepting state of one of these automata, following a path labeled by some string in L{R) or L{S), respectively. Once we reach the at:cepting state of the automaton for R or S, we can follow one of the e-arcs to the accepting state of the new automaton. Tims, the huiguage of the automaton in Fig. 3.17(a) is L(R) U L{S). 2. The expression is RS for some smaller expressions R and S. The automaton for the concatenation is shown in Fig. 3.17(b). Note that the start state of the first automaton becomes the start state of the whole, and the accepting state of the sectnd automaton becomes the accepting state of the whole. The idea is that the only paths from start to accepting state go hrst through the automaton for Я, where it must follow a path labeled by a string in L{R), and then through the automaton for S, where it follows a path labeled by a string in L(S). Thus, the paths in the automaton of Fig. 3,17(b) are all and only those labeled by strings in L{R)L{S). 3. The expression is R for some smaller expression R. Then we use the automaton of Fig. 3.17(c). That automaton allows us to go either: (a) Directly from the start state to the accepting state along a path labeled e. That path lets us accept e, which is in £-(/?) no matter what exjjression R is. (b) To the start state of the automaton for R, through that automaton one or more times, and then to the accepting state. This set of paths allows us to accept strings in £-(iJ), L{R)L(R), L{R)L{R)L{R), and so on, thus covering all strings in 1/(Л*) except perhaps e, which was covered by the direct arc to the accepting state mentioned in (3a). 4. The expression is {R) for some smaller expression R. The automaton for R also serves as the automaton for (J?), since the parentheses do not change the language defined by the expression. It is a simple observation that the constructed automata satisfy the three conditions given in the inductive hypothesis - one accepting state, with no arcs into the initial state or out of the accepting state. □ Example 3.8: Let us convert the regular expression (0 + 1)* 1(0 + 1) to an e-NFA. Our first step is to construct an automaton for 0 4- 1. We use two automata constructed according to Fig. 3.16(c), one with label 0 on the arc and one with label 1. These two automata are then combined using the union ctmstruction of Fig, 3.17(a). The result is shown in Fig. 3,18(a). Next, we apply to Fig. 3.18(a) the star construction of Fig. 3.17(c). This automaton is shown in Fig. 3,18(b). The last two steps involve applying the concatenation construction of Fig. 3.17(b). First, we connect the automaton of Fig. 3.18(b) to another automaton designed to accept only the string 1, This automaton is another application of the basis construction of Fig, 3,16(c) with label 1 on the arc. Note that we must create a new automaton to recognize 1; we must not use the automaton for 1 that was part of Fig, 3.18(a), The third automaton in the concatenation is another automaton for 0-1-1. Again, we must create a copy of the automaton of Fig. 3.18(a); we must not use the same copy that became part of Fig. 3.18(b), The complete automaton is shown in
|
|||||||||||||