
|
| |
Строительный блокнот Automata methods and madness  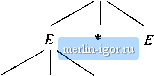 Figure 5.17: Two parse trees with the same yield The difference between these two derivations is significant. As far as the structure of the expressions is concerned, derivation (1) says that the second and tlurd expressions are multiphed, and the result is added to the first expression, while derivation (2) adds the first two expressions and multiplies the result by the third. In more concrete terms, the first derivation suggests that 1 + 2*3 should be grouped 1 + (2 * 3) = 7, while the second derivation suggests the same expression should be grouped (1 + 2) * 3 - 9. Obviously, the first of these, and not the second, matches our notion of correct grouping of arithmetic expressions. Since the grammar of Fig. 5.2 gives two different structures to any string of terminals that is derived by replacing the three expressions in E + E *E by identifiers, we see that this grammar is not a good one for providing unique structure. In particular, луЫ1е it can give strings the correct grouping as arithmetic expressions, it also gives them incorrect groupings. To use this expression grammar in a compiler, we would have to modify it to provide only the correct groupings. □ On the other hand, the mere existence of different derivations for a string {as opposed to different parse trees) does not imply a defect in the grammar. The following is an example. Example 5.26: Using the same expression grammar, we find that the string a-i-b has many different derivations. Two examples are: Example 5.25: For instance, consider the sentential form E E * E. It has two derirations from E: 1. EE + E E-E*E 1. E=>E*EE-\-E*E Notice that in derivation (1), the second E is replaced by E * E, while in derivation (2), the first E is replaced by E + E . Figure 5.17 shows the two parse trees, which we should note are distinct trees. 1. EE + EI+Ea + E=a + I=a + b 2. EE + EE + II + II + ba + b However, there is no real difference between the structures provided by these derivations; they each say that a and b are identifiers, and that then values are to be added. In fact, both of these derivations produce the same parse tree if the construction of Theorems 5.18 and 5.12 are applied. □ The two examples above suggest that it is not a multiplicity of derivations that cause ambiguity, but rather the existence of two or more parse trees. Thus, we say a CFG G - (V,T,P,S) is ambiguous if there is at least one string w in T* for which we can find two different parse trees, each with root labeled 5 and yield w. If each string has at most one parse tree in the grammar, then the grammar is unambiguous. For instance, Example 5.25 almost demonstrated the ambiguity of the grammar of Fig. 5.2. We have only to show that the trees of Fig. 5.17 can be completed to have terminal yields. Figure 5,18 is an example of that completion. 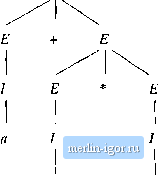 Figure 5.18: Trees with yield a + a * a, demonstrating the ambiguity of our expression grammar 5.4-2 Removing Ambiguity From Grammars In an ideal world, we would be able to give you an algorithm to remove ambiguity from CFGs, much as we were able to show an algorithm in Sectitin 4.4 to remove inmecessary states of a finite automaton. However, the surprising fact is, as we .shall .show in Section 9.5.2, that there is no algorithm whatsoever that can even tell us whether a CFG is ambiguous in the first place. Moreover, we Ambiguity Resolution in YACC If the expressif)n grammar we have been using is ambiguous, we might wonder whether the sample YACC program of Fig. 5.11 is realistic. True, the underlying grammar is ambiguous, but much of the power of the YACC parser-generator comes from providing the user with simple mechanisms for resolving most of the common causes of ambiguity. For the expression grammar, it is sufficient to insist that: a) * takes precedence over That is, *s must be grouped before adjacent -bs on either side. This rule tells us to use derivation (1) in Example 3.25, rather than derivation (2), b) Both * and + are left-associative. That is, group sequences uf expressions, all of which are connected by *, from the left, and do the same for sequences connected by +. YACC allows us to state the precedence of operators by listing them in order, from lowest tu highe.st precedence. Technically, the precedence of an operator applies to the use of any production of which that operator is the rightmost terminal in the body. We can also declare operators to be left- or right-associative with the keywords /.left and */,right. For instance, to declare that + and * were both left associative, with * taking precedence over +, we would put ahead of the grammar of Fig. 5.11 the statements: /.left + /left shall see in Section 5.4,4 that there are context-free languages tliat have nothing but ambiguous CFGs; for these languages, removal of ambiguity is impossible. Fortunately, the situation in practice is not so grim. For the sorts of constructs that appear in common programming languages, there are well-known techniques for eliminating ambiguity. The problem with the expression grammar of Fig. 5.2 is typical, and we sliall explore the elimination of its ambiguity as an important illustration. First, let us note that there are two causes of ambiguity in the grammar of Fig, 5.2: 1. The precedence of operators is not respected. While Fig, 5,17(a) properly groups the * before the + operator. Fig 5.17(b} is also a vahd parse tree and groups the -J- ahead of the *. We need to force only the structure of Fig. 5,17(a) to be legal in an unambiguous grammar.
|