
|
| |
|
Строительный блокнот Automata methods and madness 7.2 The Pumping Lemma for Context-Free Languages Now, we shall develop a tool for showing that certain languages are not context-free. The theorem, called the pumping lemma for context-free languages, says that in any sufficiently long string in a CFL, it is possible to find at most two short, nearby substrings, that we can pump in tandem. That is, we may repeat both of the strings г times, for any integer г, and the resulting string will still be in the language. We may contrast this theorem with the analogous pumping lemma for regular languages. Theorem 4.1, which says we can always find one small string to pump. The difference is seen when we consider a language like L - {0 1 j n > 1}. We can show it is not regular, by fixing n and pumping a substring of Os, thus getting a string with more Os than Is. However, the CFL pumping lemma states only that we can find two small strings, so we might be forced to use a string of Os and a string of Is, thus generating only strings in L when we pump. That outcome is fortunate, because L is a CFL, and thus we should not be able to use the CFL pumping lemma to construct strings not in L. 7.2.1 The Size of Parse Trees Our first step in deriving a pumping lemma for CFLs is to examine the shape and size of parse trees. One of the uses of CNF is to turn parse trees into binary trees. These trees have some convenient properties, one of which we exploit here. Theorem 7.17: Suppose we have a parse tree according to a Chomsky-Normal-Form grammar G - (V, T, P, .S), and suppose that the yield of the tree is a terminal string w. If the length of the longest path is n, then \w\ < 2 ~. PROOF: The proof is a simple induction on n. BASIS: n - 1. Recall that the length of a path in a tree is the number of edges, i.e., one less than the number of nodes. Thus, a tree with a maximum path length of 1 consists of only a root and one leaf labeled by a terminal. String w is this terminal, so \w\ - 1. Since 2 - = 2 = 1 in this case, we have proved the basis. INDUCTION: Suppose the longest path has length n, and n > 1. The root of the tree uses a production, which must be of the form A ВС, since тг > 1; i.e., we could not start the tree using a production with a terminal. No path in the subtrees rooted at В and С can have length greater than тг - 1, since these paths exclude the edge from the root to its child labeled В or C. Thus, by the inductive hypothesis, these two subtrees each have yields of length at most 2 . The yield of the entire tree is the concatenation of these two yields, and therefore has length at most 2 ~ -\-2~ = 2 ~4 Thus, the inductive step is proved. □ 7.2.2 Statement of the Pumping Lemma The pumping lemma for CFLs is quite similar to the pumping lemma for regular languages, but we break each string z in the CFL L into five parts, and we pump the second and fourth, in tandem. Theorem 7,18: (The pumping lemma for context-free languages) Let L be a CFL, Then there exists a constant n such that if z is any string in L such that \z\ is at least n, then we can write z = uvwxy, subject to the following conditions: 1. \vwx\ < n. That is, the middle portion is not too long. 2. vx Ф €. Since v and x are the pieces to be pumped, this condition says that at least one of the strings we pump must not be empty. 3. For alH > 0, uv%i*y is in L. That is, the two strings v and x may be pumped any number of times, including 0, and the resulting string will still be a member of L. PROOF: Our first step is to find a Chomsky-Normal-Form grammar G for L. Technically, we cannot find such a grammar if L is the CFL 0 or {c}. However, if L = 0 then the statement of the theorem, which talks about a string z in L surely cannot be violated, since there is no such z in 0. Also, the CNF grammar G will actually generate L - {e}, but that is again not of importance, since we shall surely pick n > 0, in which case z cannot be e anyway. Now, starting with a CNF grammar G = iV,T,P,S) such that L(G) ~ L - {e}, let G have m variables. Choose n = 2 . Next, suppose that г in L is of length at least n. By Theorem 7.17, any parse tree whose longest path is of length m or less must have a yield of length 2* = n/2 or less. Such a parse tree cannot have yield z, because z is too long. Thus, any parse tree with yield z has a path of length at least m -I-1. Figure 7.5 suggests the longest path in the tree for z, where к is at least m and the path is of length k+1. Since к >m, there are at least m + 1 occurrences of variables j4o, Ai,.. Ajt on the path. As there are only m different variables in V, at least two of the last m + I variables On the path (that is, Akm through Ak, inclusive) must be the same variable. Suppose Ai = Aj, where k~m<i<j<k. Then it is possible to divide the tree as shown in Fig. 7.6, String w is the yield of the subtree rooted at Aj. Strings v and x are the strings to the left and right, respectively, of w in the yield of the larger subtree rooted at А . Note that, since there are no unit productions, v and x could not both be e, although one could be. Finally, и and у are those portions of z that are to the left and right, respectively, of the subtree rooted at Ai. 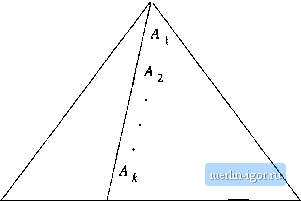 Figure 7.5: Every sufficiently long string in L must have a long path in its parse tree If At = Aj = j4, then we can construct new parse trees from the original tree, as suggested in Fig. 7.7(a}. First, we may replace the subtree rooted at Aj, which has yield vwx, by the subtree rooted at Aj, which has yield w. The reason we can do so is that both of these trees have root labeled A. The resulting tree is suggested in Fig. 7.7(b); it has yield uwy and corresponds to the case i = 0 in the pattern of strings uv*wxy. Another option is suggested by Fig. 7.7(c). There, we have replaced the subtree rooted at Aj by the entire subtree rooted at A. Again, the justification is that we are substituting one tree with root labeled A for another tree with the same root label. The yield of this tree is uvwxy. Were we to then replace the subtree of Fig. 7.7(c) with yield w by the larger subtree with yield vwx, we would have a tree with yield uvwxy, and so on, for any exponent i. Thus, there are parse trees in G for all strings of the form uvwx-y, and we have almost proved the pumping lemma. The remaining detail is condition (1), which says that \vwx\ < n. However, we picked to be close to the bottom of the tree; that is, к ~ i < m. Thus, the longest path in the subtree rooted at Aj is no greater than m + 1. By Theorem 7.17, the subtree rooted at At has a yield whose length is no greater than 2 = n. □ 7.2.3 Applications of the Pumping Lemma for CFLs Notice that, like the earlier pumping lemma for regular languages, we use the CFl pumping lemma as an adversary game, as follows. 1. We pick a language L that we want to show is not a CFL.
|