
|
| |
|
Строительный блокнот Automata methods and madness If we review the construction of grammar productions from a rule like 6{q,a,X) contains {ro,YiY2 Yk), we note that it gives rise to a collection of productions of the form [дХгк] [roY-iri][riY2r2] [rk-iYkrk] for aJl Usts of states Г1,Г2,... ,rjt. As к could be close to n, and there could be close to n states, the total number of productions grows as n . We cannot carry out such a construction for reasonably sized PDAs if the PDA has even one long stack string to write. Fortunately, this worst case never has to occur. As was suggested by Exercise 6.2.8, we can break the pushing of a long string of stack symbols into a sequence of at most n steps that each pushes one symbol. That is, if 6{q, a, X) contains (го,УгV2 Jfc), we may introduce new states Р2,Рз, -.Pk-i- Then, we replace (ro,FiF2 -Уь) in 6{q,a,X) by (р-г.У-гУк), and introduce the new transitions 5(pjt-l,n-l) = {(pk-2,Yk~2Yk-l)), 6{pk-2.Yk-2) = {(рк-3,П-зП-2)} and so on, down to (р2,У2) = {{ro, 12)}- Now, no transition has more than two stack symbols. We have added at most n new states, and the total length of all the transition rules of 6 has grown by at most a constant factor; i.e., it is still 0{n). There are 0(n) transition rules, and each generates O(n) productions, since there are only two states that need to be chosen in the productions that come from each rule. Thus, the constructed grammar has length 0{n) and can be constructed in cubic time. We summarize this informal analysis in the theorem below. Theorem 7.31: There is an 0(n) algorithm that takes a PDA P whose representation has length n and produces a CFG of length at most O(n). This CFG generates the same language as P accepts by empty stack. Optionally, we can cause G to generate the language that P accepts by final state. □ 7.4.2 Running Time of Conversion to Chomsky Normal Form As decision algorithms may depend on first putting a CFG into Chomsky Normal Form, we should also look at the running time of the various algorithms that we used to convert an arbitrary grammar to a CNF grammar. Most of the steps preserve, up to a constant factor, the length of the grammars description; that is, starting with a grammar of length n they produce another grammar of length 0{n). The good news is summarized in the following list of observations: 1. Using the proper algorithm (See Section 7.4,3), detecting the reachable and generating symbols of a grammar can be done in 0(n) time. Eliminating the resulting useless symbols takes 0{n) time and does not increase the size of the grammar. 2. Constructing the unit pairs and eliminating unit productions, as in Section 7.1.4, takes O(n) time and the resulting grammar has length O(n). 3. The replarement of termmals by variables in production bodies, as in Section 7.1.5 (Chomsky Normal Form), takes 0{n) time and results in a grammar whose length is 0{n). 4. The breaking of production bodies of length 3 or more into bodies of length 2, as carried out in Section 7.1.5 also takes 0(n) time and results in a grammar of length 0{n). The bad news concerns the construction of Section 7.1.3, where we ehminate c-productions. If we have a production body of length k, we could construct from that one production 2* - 1 productions for the now grammar. Since к could be proportional to n, this part of the construction could take 0(2 ) time and result in a grammar whose length is 0(2 ). To avoid this exponential blowup, we need only to bound the length of production bodies. The trick of Section 7.1.5 can be applied to any production body, not just to one without terminals. Thus, we recommend, as a preliminary step before eliminating c-productions, the breaking of all long production bodies into a sequence of productions with bodies of length 2. This step takes 0(n) time and grows the grammar only linearly. The construction of Section 7.1.3, to ehminate (-productions, will work on bodies of length at most 2 in such a way that the running time is 0(n) and the resulting grammar has length 0{n). With this modification to the overall CNF construction, the only step that is not lineal is the elimination of unit productions. As that step is O(n), we conclude the following: Theorem 7.32: Given a grammar G of length n, we can find an equivalent Chomsky-Normal-Form grammar for G in time O(n); the resulting grammar has length O(n-). □ 7.4.3 Testing Emptiness of CFLs Wa have alnady seen the algorithm for testing whether a CFL L is empty. Given a grannnar G for the language L, use the algorithm of Section 7.1.2 to decide whether the start symbol 5 of G is generatmg, i.e., whether S derives at least one string. L is empty if and only if S is not generating. Because of the importance of this test, we shall consider in detail how much time it takes to find all the generating symbols of a grammar G. Suppose the length of G is n. Then there could be on the order of n variables, and each pass of the inductive discovery of generating variables could take 0(n) time to examine all the productions of G. If only one new generating variable is disco\ered on each pass, then there could be 0{n) passes. Thus, a naive implementation of the generating-symbols test is O(n). However, there is a more careful algorithm that sets up a data structure in advance to make our disco\ery of generating symbols take 0{n) time ordy. The data structure, suggested in Fig. 7.11, starts with an array indexed by the variables, as shown on the left, which tells whether or not we have established that the variable is generating. In Fig. 7.11, the array suggests that we have discovered В is generating, but we do not know whether or not A is generating. At the end of the algorithm, each question mark will become no, since any variable not discovered by the algorithm to be generating is in fact nongenerating. Generating? 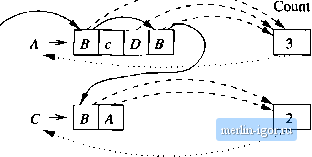 Figure 7.11: Data structure for the hnear-time emptiness test The productions are preprocessed by setting up several kinds of useful links. First, for each variable there is a chain of all the positions in which that variable appears. For instance, the chain for variable В is suggested by the solid lines. For each production, there is a count of the uumber of positions holding variables whose ability to generate a terminal string has not yet been taken into account. The dashed lines suggest links from the productions to their counts. The counts shown in Fig. 7.11 suggests that we have not yet taken any of the variables into account, even though we just established that В is generating. Suppose that we have discovered that В is generating. We go down the list of positions of the bodies holding B. For each such position, we decrement the count for that production by 1; there is now one fewer position we need to find generating in order to conclude that the variable at the head is also generating. If a count reaches 0, then we know the head variable is generating. A link, suggested by the dotted lines, gets us to the variable, and we may put that variable on a queue of generating variables whose consequences need to be explored (as we just did for variable B). This queue is not shown. We must argue that this algorithm takes 0{n) time. The important points are as follows: Since there are at most n variables in a grammar of size 7i, creation and initialization of the array takes 0{n) time. There are at most n productions, and their total length is at most n, so initialization of the links and counts suggested in Fig. 7.11 can be done in 0(n) time. When we discover a production has count 0 {i.e., all positions of its body are generating), the work involved can be put into two categories:
|