
|
| |
|
Строительный блокнот Automata methods and madness Other Uses for the Linear Emptiness Test The* кате data structure aud accounting trick that we used in Section 7.4.3 to test whether a variable is generating can be used to make some of the oth(>r tests of Section 7.1 linear-time. Two important examples are: 1. Whicli symbols are reachable? 2. Which svmbols are nuUable? 1. Work done for that production: discovering the count is 0, finding which variable, say A, is at the head, checking whether it is already known to be generating, and putting it on the queue if not. All these steps ar<! 0(1) for each production, and so at most 0(n) work of this type is done in total. 2. Work done when visiting the positions of the production bodies that have the head variable A. This work is proportional to the number of positions with .4. Therefore, the aggregate amount of work done processing all generating symbols is proportional to the sum of the lengths of the production bodies, and that is 0(n). We conclude that the total work done by this algorithm is 0{n). 7.4.4 Testing Membership in a CFL We can also deci<le membership of a string w in a CFL L. There are several inefficient ways to make the test; th(y take time that is exponential in \w\, as,suming a grammar or PDA for the langnage L is given and its size is treated as a constant, independent of w. For instance, start by converting whatever representation of L we are given into a CNF grammar for L. As the parse trees of a Chomsky-Normal-Form grammar are binary trees, if w is of length n then there will be exactly 2ti - 1 nodes labeled by variables in the tree (that result has an easy, inductive proof, which we leave to you). The number of possible trees and node-labc!lings is thus only exponential in n, so in principle we can list them all and chc>ck to see if any of them yields w. There is a nmch more efficient techiuque based on the idea of dynamic prograimning, which may also be known to you as a table-filluig algorithm or tabulation. This algorithm, known as the CYK Algorithm, starts with a CNF grammar G = (V,T, P,S) for a language L. The input to the algorithm is a string w - ai 2 * in T*. In 0(71) time, the algorithm constructs a table it i.j namnd after three people, each of whom independently discovered essentially the same idea; J. Cocke, П. Younger, and T. Kasami. that tells whether w is in L. Note that when computing this running time, the grammar itself is considered fixed, and its size contributes only a constant factor to the running time, which is measured in terms of the length of the string w whose membership in L is being tested. In the CYK algorithm, we construct a triangular table, as suggested in Fig. 7.12. The horizontal axis corresponds to the positions of the string w = aia2 - ttn, which we have supposed has length 5. The table entry X,j is the set of variables A such that A => aiOi+i aj. Note in particular, that we are interested in whether S is in the set because that is the same as saying S %u, i.e., UI is in L. Figure 7.12: The table constructed by the CYK algorithm To fill the table, we work row-by-row, upwards. Notice that each row corresponds to one length of substrings; the bottom row is for strings of length 1, the second-from-bottom row for strings of length 2, and so on, until the top row corresponds to the one substring of length n, which is w itself It takes 0{n) time to compute any one entry of the table, by a method we shall discuss next. Since there are n(n + l)/2 table entries, the whole table-construction process takes 0{n?) time. Here is the algorithm for computing the Xjs: BASIS: We compute the first row as follows. Since the string beginning and ending at position i is just the terminal Oi, and the grammar is in CNF, the only way to derive the string at is to use a production of the form Л -) o,;. Thus, Xii is the set of variables A such that Л Oj is a production of G. INDUCTION: Suppose we want to compute Xij, which is in row j - i -b 1, and we have computed all the Xs in the rows below. That is, we know about all strings shorter than aiOt-)-] - Oj, and in particular we know about all proper prefixes and proper suffixes of that string. As j - г > 0 may be assumed (since the case г = j is the basis), we know that any derivation A atui-y] aj must start out with some step A => BO. Then, В derives some prefix of a,ai+i aj, say В а.;а;+1 uk, for some к < j. Also, С must then derive the remainder of aiOi-j-i uj, that is, С aft+iajt+2 Oj- We conclude that in order for A to be in Xij, we must find variables В and C, and integer A; such that: 1. г <k < j. 2. В is in Xi. 3. С is in Xk+ij- 4. A is a production of G. Finding such variables A requires us to compare at most n pairs of previously computed sets: (Xn,Xi+]j), {Xji+i,Xi+2j), and so on, until JVjj). The pattern, in which we go up the column below Х;, at the same time we go down the diagonal, is suggested by Fig. 7.13. 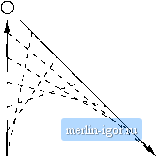 Figure 7.13: Computation of Xij requires matching the column below with the diagonal to the right Theorem 7.33: The algorithm described above correctly computes Xjj for all i and j; thus w is in L{G) if and only if S is in Хщ- Moreover, the running time of the algorithm is 0(n). PROOF: The reason the algorithm finds the correct sets of variables was explained as we introduced the basis and inductive parts of the algorithm. For the running time, note that there are O(n) entries to compute, and each involves comparing and computing with n pairs of entries. It is important to remember that, although there can be many variables in each set Xj, the grammar G is fixed and the number of its variables does not depend on n, the length of the string w whose membership is being tested. Thus, the time to compare two entries Xik and Xk+i,j, and find variables to go into Xij is 0(1). As there are at most n such pairs for each Xij, the total work is O(n). □
|